# Load data
data(mtcars)
# Bivariate regression
lm_bivariate <- lm(mpg ~ hp, data = mtcars)
# Multivariate regression (adding weight as control)
lm_multivariate <- lm(mpg ~ hp + wt, data = mtcars)5 Multivariate Regression
TipKey Questions
- Why do we need multivariate regression?
- How do we interpret coefficients when there are multiple independent variables?
- What is the zero conditional mean assumption in the multivariate case?
- How does multivariate OLS function as a “matching” estimator?
- What is the omitted variable bias formula and how do we use it?
- What is the bias-variance tradeoff when deciding which controls to include?
NoteSuggested Readings
- Wooldridge (2019), Ch. 3
In Chapter 4, we introduced bivariate OLS and saw that causal interpretation requires the zero conditional mean assumption: \(E[\mu | x] = 0\). We also saw that this assumption is very difficult to justify.
This chapter introduces multivariate OLS, which allows us to explicitly control for confounding variables. By including additional variables on the right-hand side of our regression, we can make the zero conditional mean assumption more plausible and get closer to causal estimates.
5.1 The Problem with Bivariate OLS
Let’s revisit why bivariate OLS often fails to give us causal estimates.
Consider a regression of wages on education:
\[ wage = \beta_0 + \beta_1 \cdot educ + \mu \]
For \(\hat{\beta}_1\) to be an unbiased estimate of the causal effect of education, we need \(E[\mu | educ] = 0\). But the error term \(\mu\) contains everything else that affects wages: ability, family connections, motivation, and countless other factors.
Many of these factors are likely correlated with education. For example, people from wealthier families tend to get more education (better schools, tutors, college is affordable) and earn higher wages (family connections, inherited wealth). If family income is in \(\mu\) and correlated with education, then \(E[\mu | educ] \neq 0\), and our estimate is biased.
ImportantThe Core Problem
With bivariate OLS, the zero conditional mean assumption requires that all factors affecting \(y\) (other than \(x\)) be uncorrelated with \(x\). This is almost never plausible in observational data.
5.2 The Multivariate Solution
Multivariate OLS offers a solution: explicitly control for variables that might be confounders.
If we’re worried that family income confounds the education-wage relationship, we can include it in our population regression model by simply adding additional right-hand side, independent variables:
\[ wage = \beta_0 + \beta_1 \cdot educ + \beta_2 \cdot family\_income + \mu \]
Now \(\beta_1\) represents the effect of education on wages holding family income constant. The error term \(\mu\) no longer contains family income, so that specific source of bias is eliminated.
5.2.1 The General Multivariate Model
If we are worried about additional sources of omitted variable bias (as we probably should be), it is easy to expand our regression model and include even more control variables.
The general multivariate linear regression model with \(k\) independent variables is:
\[ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_k x_k + \mu \tag{5.1}\]
where:
- \(y\) is the dependent variable
- \(x_1, x_2, \ldots, x_k\) are the independent/control variables
- \(\beta_0\) is the intercept
- \(\beta_j\) is the coefficient on \(x_j\) (for \(j = 1, 2, \ldots, k\))
- \(\mu\) is the error term containing all factors not included in the model
5.2.2 Interpreting Coefficients
In multivariate regression, each coefficient has a ceteris paribus interpretation:
\[ \beta_j = \frac{\partial y}{\partial x_j} \]
This is the change in \(y\) associated with a one-unit increase in \(x_j\), holding all other independent variables constant.
For example, in the model:
\[ wage = \beta_0 + \beta_1 \cdot educ + \beta_2 \cdot family\_income + \mu \]
- \(\beta_1\): The change in wages for one additional year of education, holding family income constant
- \(\beta_2\): The change in wages for one additional dollar of family income, holding education constant
5.2.3 The Zero Conditional Mean Assumption
In multivariate OLS, the zero conditional mean assumption becomes:
\[ E[\mu | x_1, x_2, \ldots, x_k] = 0 \]
This states that the average of unobserved factors is zero for all unique combinations of the independent variables. In other words, everything in \(\mu\) must be uncorrelated with all the variables we’ve included.
This assumption is much more plausible than its bivariate counterpart. By including relevant control variables, we’ve removed them from \(\mu\), making it more likely that what remains is uncorrelated with our variables of interest.
5.3 Deriving the Multivariate OLS Estimator
The derivation follows the same logic as bivariate OLS: we minimize the sum of squared residuals.
5.3.1 The Minimization Problem
Given a sample of \(n\) observations, we want to find values \(\hat{\beta}_0, \hat{\beta}_1, \ldots, \hat{\beta}_k\) that minimize:
\[ SSR = \sum_{i=1}^{n} (y_i - \hat{\beta}_0 - \hat{\beta}_1 x_{1i} - \hat{\beta}_2 x_{2i} - \cdots - \hat{\beta}_k x_{ki})^2 \]
5.3.2 First-Order Conditions
Taking partial derivatives with respect to each \(\hat{\beta}_j\) and setting them equal to zero yields \(k + 1\) first-order conditions:
\[ \sum_{i=1}^{n}(y_i - \hat{\beta}_0 - \hat{\beta}_1 x_{1i} - \cdots - \hat{\beta}_k x_{ki}) = 0 \]
\[ \sum_{i=1}^{n} x_{1i}(y_i - \hat{\beta}_0 - \hat{\beta}_1 x_{1i} - \cdots - \hat{\beta}_k x_{ki}) = 0 \]
\[ \vdots \]
\[ \sum_{i=1}^{n} x_{ki}(y_i - \hat{\beta}_0 - \hat{\beta}_1 x_{1i} - \cdots - \hat{\beta}_k x_{ki}) = 0 \]
Solving this system of equations yields the OLS estimates. The algebra is tedious (and typically handled with matrix methods), so we won’t derive the explicit formulas here. Fortunately, your computer does this effortlessly.
5.4 Estimating Multivariate OLS in R
In R, we estimate multivariate regression using the same lm() function, simply adding variables with the + symbol.
5.4.1 Example: MPG, Horsepower, and Weight
Let’s estimate the effect of horsepower on fuel efficiency, first without and then with a control for vehicle weight.
Bivariate results:
summary(lm_bivariate)
Call:
lm(formula = mpg ~ hp, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-5.7121 -2.1122 -0.8854 1.5819 8.2360
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 30.09886 1.63392 18.421 < 2e-16 ***
hp -0.06823 0.01012 -6.742 1.79e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.863 on 30 degrees of freedom
Multiple R-squared: 0.6024, Adjusted R-squared: 0.5892
F-statistic: 45.46 on 1 and 30 DF, p-value: 1.788e-07Multivariate results:
summary(lm_multivariate)
Call:
lm(formula = mpg ~ hp + wt, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-3.941 -1.600 -0.182 1.050 5.854
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 37.22727 1.59879 23.285 < 2e-16 ***
hp -0.03177 0.00903 -3.519 0.00145 **
wt -3.87783 0.63273 -6.129 1.12e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.593 on 29 degrees of freedom
Multiple R-squared: 0.8268, Adjusted R-squared: 0.8148
F-statistic: 69.21 on 2 and 29 DF, p-value: 9.109e-125.4.2 Interpreting the Results
In the bivariate regression, the coefficient on horsepower is \(-0.068\): each additional unit of horsepower is associated with 0.068 fewer miles per gallon.
In the multivariate regression (controlling for weight), the coefficient on horsepower drops to \(-0.032\)—less than half the size!
What happened? Horsepower and weight are positively correlated (more powerful engines tend to be in heavier vehicles), and weight independently reduces fuel efficiency. The bivariate estimate was conflating the effect of horsepower with the effect of weight. Once we control for weight, we isolate the effect of horsepower alone.
TipWhat Changed?
The coefficient on hp dropped from \(-0.068\) to \(-0.032\) when we added wt. This suggests that much of what appeared to be the “effect” of horsepower was actually the effect of weight. This is precisely what controlling for confounders accomplishes.
5.5 Multivariate OLS as Matching
What is actually happening “under the hood” when we say we want to “control” for a given variable?
There’s an intuitive way to understand what multivariate OLS does: it’s essentially a matching estimator. When we “control for” a variable, we’re comparing observations (i.e., values of \(x_1\)) that have similar values of a control variable (ie., \(x_2\)).
5.5.1 The Returns to Education Example
Suppose we want to estimate the effect of education on wages. A simple comparison of average wages across education levels might be misleading because people with more education tend to work in higher-paying industries. Part of the apparent “return to education” might actually be an “industry premium.”
Let’s work through this with simulated data to see exactly how controlling for industry works.
Specifically, let’s create an imaginary population where:
- Individuals have either 12. 14, or 16 years of education
- Those with 12, 14, and 16 years of education have a 0.20, 0.40, and 0.65 chance of working in a high-paying industry
- The “true” population regression model is:
\[ wage = 25000 + 3000 \cdot \text{education} + 15000 \cdot \text{professional industry} \]
So, the “true” effect of an additional year of education on wages is thus 3000.
Code: Simulated Population Data
# Simulate wage data
set.seed(12345)
n <- 5000
# Create data where:
# - More educated workers are more likely to be in high-paying industries
# - Industry independently affects wages
wage_data <- tibble(
# Education: 1 = HS, 2 = Some College, 3 = Bachelor's+
educ_years = sample(c(12, 14, 16), n, replace = TRUE, prob = c(0.4, 0.3, 0.3)),
# Higher education -> more likely in professional services (high pay industry)
ind_professional = rbinom(n, 1, prob = case_when(
educ_years == 12 ~ 0.20,
educ_years == 14 ~ 0.40,
educ_years == 16 ~ 0.65
)),
# Wages depend on education AND industry
wage = 25000 +
3000 * (educ_years - 12) + # True education effect: $3000 per year
15000 * ind_professional + # Industry premium: $15000
rnorm(n, 0, 8000)
) |>
mutate(
educ_cat = case_when(
educ_years == 12 ~ "HS Only",
educ_years == 14 ~ "Some College",
educ_years == 16 ~ "Bachelor's+"
),
industry = ifelse(ind_professional == 1, "Professional", "Other")
)5.5.2 The Naive Comparison
First, let’s compute average wages by education level without any controls:
naive_means <- wage_data |>
group_by(educ_cat, educ_years) |>
summarise(avg_wage = mean(wage), n = n(), .groups = "drop") |>
arrange(educ_years)
naive_means |>
knitr::kable(
col.names = c("Education", "Years", "Avg Wage ($)", "N"),
digits = 0
)| Education | Years | Avg Wage ($) | N |
|---|---|---|---|
| HS Only | 12 | 28060 | 1994 |
| Some College | 14 | 36499 | 1508 |
| Bachelor’s+ | 16 | 47005 | 1498 |
The naive comparison suggests that going from high school to some college is associated with about $8,439 higher wages, and going from high school to a bachelor’s degree is associated with about $18,945 higher wages (i.e., the difference between average wages for those with only 12 years of education vs. 14 years, and so on).
But wait! The true effect of education in our simulation is only $3,000 per year (so $6,000 for 2 extra years and $12,000 for 4 extra years). The naive estimates are too large!
We can also see this in the results if we run a simple bivariate regression:
naive_ols <- lm(wage ~ educ_years, data = wage_data)
summary(naive_ols)
Call:
lm(formula = wage ~ educ_years, data = wage_data)
Residuals:
Min 1Q Median 3Q Max
-31072 -7558 -354 7555 34592
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -28775.40 1250.54 -23.01 <2e-16 ***
educ_years 4713.69 89.96 52.40 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 10560 on 4998 degrees of freedom
Multiple R-squared: 0.3546, Adjusted R-squared: 0.3544
F-statistic: 2745 on 1 and 4998 DF, p-value: < 2.2e-16The coefficient on educ_years is way bigger than the true effect!
This is because more educated workers are more likely to be in high-paying industries. By failing to account that some industries just pay higher than others, our simple
5.5.3 Step 1: Compute Within-Industry Differences
To control for industry, we first compute average wages separately for each education-industry combination:
cell_means <- wage_data |>
group_by(industry, educ_cat, educ_years) |>
summarise(avg_wage = mean(wage), n = n(), .groups = "drop") |>
arrange(industry, educ_years)
cell_means |>
select(industry, educ_cat, avg_wage, n) |>
knitr::kable(
col.names = c("Industry", "Education", "Avg Wage ($)", "N"),
digits = 0
)| Industry | Education | Avg Wage ($) | N |
|---|---|---|---|
| Other | HS Only | 24925 | 1583 |
| Other | Some College | 30793 | 939 |
| Other | Bachelor’s+ | 37385 | 515 |
| Professional | HS Only | 40136 | 411 |
| Professional | Some College | 45915 | 569 |
| Professional | Bachelor’s+ | 52044 | 983 |
Now let’s compute the wage differences within each industry:
within_industry <- cell_means |>
group_by(industry) |>
mutate(
diff_from_hs = avg_wage - avg_wage[educ_years == 12]
) |>
filter(educ_years > 12) |>
select(industry, educ_cat, diff_from_hs, n)
within_industry |>
knitr::kable(
col.names = c("Industry", "Education", "Wage Diff vs HS ($)", "N in Cell"),
digits = 0
)| Industry | Education | Wage Diff vs HS ($) | N in Cell |
|---|---|---|---|
| Other | Some College | 5868 | 939 |
| Other | Bachelor’s+ | 12461 | 515 |
| Professional | Some College | 5779 | 569 |
| Professional | Bachelor’s+ | 11908 | 983 |
Notice that the within-industry differences are much closer to the true values ($6,000 for Some College, $12,000 for Bachelor’s+).
5.5.4 Step 2: Compute Weights
To combine these within-industry estimates into a single number, we take a weighted average. The weights are based on the number of observations in each industry:
# Total workers in each industry
industry_totals <- wage_data |>
count(industry) |>
mutate(weight = n / sum(n))
industry_totals |>
knitr::kable(
col.names = c("Industry", "N", "Weight"),
digits = 3
)| Industry | N | Weight |
|---|---|---|
| Other | 3037 | 0.607 |
| Professional | 1963 | 0.393 |
5.5.5 Step 3: Compute Weighted Average
Now we combine the within-industry differences using these weights. Let’s do this for the Bachelor’s+ vs HS comparison:
# Get the within-industry differences for Bachelor's+
ba_diffs <- within_industry |>
filter(educ_cat == "Bachelor's+") |>
left_join(industry_totals, by = "industry")
ba_diffs |>
select(industry, diff_from_hs, weight) |>
knitr::kable(
col.names = c("Industry", "Within-Industry Diff ($)", "Weight"),
digits = c(0, 0, 3)
)| Industry | Within-Industry Diff ($) | Weight |
|---|---|---|
| Other | 12461 | 0.607 |
| Professional | 11908 | 0.393 |
# Weighted average
weighted_avg <- sum(ba_diffs$diff_from_hs * ba_diffs$weight)The weighted average is:
\[ (1.2461\times 10^{4} \times 0.607) + (1.1908\times 10^{4} \times 0.393) = 12,244 \]
This is much closer to the true effect of $12,000!
5.5.6 The Regression Equivalent
Now let’s see what regression gives us:
# Create numeric education variable (years beyond HS - just to get easier to interpret numbers)
wage_data <- wage_data |>
mutate(educ_beyond_hs = educ_years - 12)
# Regression controlling for industry
lm_controlled <- lm(wage ~ educ_beyond_hs + ind_professional, data = wage_data)
summary(lm_controlled)
Call:
lm(formula = wage ~ educ_beyond_hs + ind_professional, data = wage_data)
Residuals:
Min 1Q Median 3Q Max
-28099.0 -5366.5 -53.9 5311.7 26941.5
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 24907.19 175.67 141.78 <2e-16 ***
educ_beyond_hs 3042.33 74.46 40.86 <2e-16 ***
ind_professional 15009.59 253.05 59.32 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 8088 on 4997 degrees of freedom
Multiple R-squared: 0.6212, Adjusted R-squared: 0.6211
F-statistic: 4098 on 2 and 4997 DF, p-value: < 2.2e-16The coefficient on educ_beyond_hs is approximately $3,000 per year—almost exactly the true value we built into the simulation!
Compare this to the naive regression without the industry control:
lm_naive <- lm(wage ~ educ_beyond_hs, data = wage_data)
coef(lm_naive)["educ_beyond_hs"]educ_beyond_hs
4713.686 The naive estimate (4,714) is inflated because it conflates the education effect with the industry premium.
NoteMultivariate OLS as Matching
When you include control variables, OLS is effectively:
- Grouping observations by similar values of the control variables
- Computing the relationship between \(x\) and \(y\) within each group
- Taking a weighted average across groups, where weights reflect group sizes
This is why multivariate regression can sometimes be thought of as a “matching” estimator—we’re matching people who work in the same industry and then comparing their wages based on education. The same logic applies if we have multiple control variables, although the grouping gets complicated fast.
5.6 Goodness-of-Fit: Adjusted R-Squared
In bivariate OLS, we used \(R^2\) to measure how much variation in \(y\) our model explains. The same concept applies to multivariate OLS, but with an important caveat.
5.6.1 The Problem with R-Squared
The \(R^2\) can never decrease when you add more variables—it can only increase or stay the same. This is because adding variables can only improve (or maintain) the fit, even if those variables are irrelevant.
This creates a problem: \(R^2\) mechanically increases as you add more variables, potentially making a bloated model look better than a parsimonious one.
5.6.2 The Adjusted R-Squared
The adjusted R-squared penalizes for the number of parameters:
\[ \bar{R}^2 = 1 - \frac{(1 - R^2)(n - 1)}{n - k - 1} \]
where \(n\) is the sample size and \(k\) is the number of independent variables.
The adjusted \(R^2\):
- Is always smaller than the regular \(R^2\)
- Can decrease when you add irrelevant variables
- Provides a better comparison between models with different numbers of variables
# Compare R-squared and Adjusted R-squared
c(
"Bivariate R-sq" = summary(lm_bivariate)$r.squared,
"Bivariate Adj R-sq" = summary(lm_bivariate)$adj.r.squared,
"Multivariate R-sq" = summary(lm_multivariate)$r.squared,
"Multivariate Adj R-sq" = summary(lm_multivariate)$adj.r.squared
) Bivariate R-sq Bivariate Adj R-sq Multivariate R-sq
0.6024373 0.5891853 0.8267855
Multivariate Adj R-sq
0.8148396 5.7 Gauss-Markov Assumptions for Multivariate OLS
The Gauss-Markov assumptions extend naturally to the multivariate case, with one important addition.
5.7.1 Assumption 1: Linear in Parameters
\[ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_k x_k + \mu \]
As in the bivariate case, we can transform variables to model non-linear relationships while maintaining linearity in parameters.
5.7.2 Assumption 2: Random Sampling
We have a random sample \(\{(x_{1i}, x_{2i}, \ldots, x_{ki}, y_i) : i = 1, \ldots, n\}\) from the population.
5.7.3 Assumption 3: No Perfect Multicollinearity
This assumption has two parts:
- No constant variables: Each independent variable must have some variation in the sample
- No exact linear relationships: No independent variable can be a perfect linear function of other independent variables
The second part is new and important in multivariate regression.
WarningPerfect Multicollinearity
Perfect multicollinearity occurs when one independent variable is an exact linear combination of others. Examples:
- Including both
family_incomeandfamily_income_thousands(one is just the other divided by 1000) - Including
parent1_income,parent2_income, andfamily_incomewhenfamily_income = parent1_income + parent2_income - Including dummy variables for all categories of a categorical variable plus an intercept
When perfect multicollinearity exists, the OLS formulas break down (the system of equations has no unique solution). R will typically drop one of the collinear variables automatically and issue a warning.
5.7.4 Assumption 4: Zero Conditional Mean
\[ E[\mu | x_1, x_2, \ldots, x_k] = 0 \]
The error term has mean zero for all combinations of the independent variables. This can still fail due to:
- Omitted variables correlated with included variables
- Wrong functional form
- Measurement error in independent variables
- Simultaneous causality
5.7.5 Assumption 5: Homoskedasticity
\[ Var(\mu | x_1, x_2, \ldots, x_k) = \sigma^2 \]
The variance of the error term is constant across all combinations of independent variable values.
5.8 Unbiasedness of Multivariate OLS
Just like with bivariate OLS, if Gauss-Markov assumptions 1–4 hold, then our multivariate OLS estimates are unbiased:
\[ E[\hat{\beta_j}] = \beta_j, j = {0, 1, ..., k}. \]
We can then interpret our estimates as ceteris paribus comparisons, or apples-to-apples comparisons conditional on control variables.
5.8.1 Observed vs. Unobserved Variables
However, just because we are able to control for lots of variables doesn’t mean we have a causal estimate. In many cases, if we have lots of observed correlation between control variables and our independent variable of interest, we also probably have lots of unobserved correlation between variables.
For example, there could be important components of \(\mu\) that we simply cannot measure sufficiently–inherent motivation in a wage regression, for example. Labor market surveys generally do not have an effective way to capture this, so this important determinant of wages is considered unobserved, and we thus have cannot include it in our multivariate regression model and we will therefore end up with a biased estimate.
But this is not the end of the world. Throughout the course, we are going to cover some methods which allow us to deal with some of these issues.
5.9 The Omitted Variable Bias Formula
Even when we can’t include an omitted variable (perhaps because it’s unobservable), we can still reason about the direction of the bias.
5.9.1 Setup
Let’s say our independent variable of interest is \(beta_1\) (e.g., education).
Suppose the true population regression model is:
\[ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \mu \]
In an ideal world, we would be able to estimate an unbiased model:
\[ \hat{y} = \hat{\beta_0} + \hat{\beta_1} x. \]
But we can’t observe \(x_2\) (it may be motivation or ability, for example), so instead we estimate the misspecified model:
\[ \tilde{y} = \tilde{\beta}_0 + \tilde{\beta}_1 x_1 \]
where the tilde (\(\tilde{}\)) indicates estimates from the misspecified model.
5.9.2 The OVB Formula
It turns out there is a simple relationship between our biased estimate from the misspecified model, \(\tilde{\beta}_1\), and our unbiased, correctly specified model \(\hat{\beta}_1\):
It can be shown that:
\[ \tilde{\beta}_1 = \hat{\beta}_1 + \hat{\beta}_2 \tilde{\delta}_1 \tag{5.2}\]
where \(\tilde{\delta}_1\) is the coefficient from regressing \(x_2\) on \(x_1\):
\[ x_2 = \tilde{\delta}_0 + \tilde{\delta}_1 x_1 + \text{error}. \]
Taking expectations:
\[ E[\tilde{\beta}_1] = \beta_1 + \beta_2 \tilde{\delta}_1 \]
Therefore, the bias is:
\[ \text{Bias}(\tilde{\beta}_1) = \beta_2 \cdot \tilde{\delta}_1 \tag{5.3}\]
5.9.3 Interpreting the Bias Formula
The bias depends on two factors:
- \(\beta_2\): The effect of the omitted variable on \(y\)
- \(\tilde{\delta}_1\): The correlation between the omitted variable (\(x_2\)) and the included variable (\(x_1\))
If either factor is zero, there is no bias. But if both are non-zero, bias exists, and its direction depends on the signs:
| \(Corr(x_1, x_2) > 0\) | \(Corr(x_1, x_2) < 0\) | |
|---|---|---|
| \(\beta_2 > 0\) | Positive bias (overestimate) | Negative bias (underestimate) |
| \(\beta_2 < 0\) | Negative bias (underestimate) | Positive bias (overestimate) |
5.9.4 Example: Education, Wages, and Ability
Consider estimating the return to education while omitting ability:
- \(\beta_2\) (effect of ability on wages): Positive (more able people earn more)
- \(\tilde{\delta}_1\) (correlation of ability with education): Positive (more able people get more education)
Therefore: \[\text{Bias} = (+)(+) = \text{Positive}\]
Our estimate of the return to education is too large—it includes part of the return to ability.
5.9.5 Example: Policing, Crime, and Poverty
Consider estimating the effect of policing on crime while omitting local poverty:
- Effect of poverty on crime (\(\beta_2\)): Positive (higher poverty → more crime)
- Correlation of poverty with policing (\(\tilde{\delta}_1\)): Positive (high-poverty areas get more policing)
Therefore: \[\text{Bias} = (+)(+) = \text{Positive}\]
Our estimate suggests policing increases crime more than it actually does (or reduces it less than it actually does). This is why naive correlations between police presence and crime can be misleading.
5.9.6 Example: Study Hours, Course Difficulty, and GPA
Consider estimating the effect of study hours on GPA while omitting course difficulty:
- Effect of course difficulty on GPA (\(\beta_2\)): Negative (harder courses → lower GPA)
- Correlation of course difficulty with study hours (\(\tilde{\delta}_1\)): Positive (harder courses → students study more)
Therefore: \[\text{Bias} = (-)(+) = \text{Negative}\]
Our estimate understates the true benefit of studying. Students who study the most tend to be taking harder courses that drag down their GPAs, so the naive estimate makes studying look less effective than it actually is.
5.10 Variance in Multivariate OLS
Under the Gauss-Markov assumptions, the variance of \(\hat{\beta}_j\) is:
\[ Var(\hat{\beta}_j) = \frac{\sigma^2}{SST_j (1 - R_j^2)} \tag{5.4}\]
where:
- \(\sigma^2\) is the error variance
- \(SST_j = \sum(x_{ji} - \bar{x}_j)^2\) is the total variation in \(x_j\)
- \(R_j^2\) is the R-squared from regressing \(x_j\) on all other independent variables
5.10.1 What Increases Variance?
From Equation 5.4, the variance of \(\hat{\beta}_j\) increases when:
- More noise (\(\sigma^2\)): Higher error variance means less precise estimates
- Less variation in \(x_j\) (\(SST_j\)): Less information about how \(x_j\) relates to \(y\)
- Higher \(R_j^2\): More correlation between \(x_j\) and other independent variables
The third point is crucial: when your variable of interest is highly correlated with control variables, your estimate becomes less precise. This is sometimes called high multicollinearity or the multicollinearity problem.
Note this is different from perfect multicolinearity, which makes it impossible to get an estimate. Here, we still will be able to estimate our \(\beta_j\) successfully, but it will have a high variance and be “noisy”.
5.10.2 Estimating \(\sigma^2\) from the Data
Look carefully at the variance formula above. The denominator contains quantities we can compute directly from our sample: \(SST_j\) (the total variation in \(x_j\)) and \(R^2_j\) (how much of \(x_j\) is explained by the other regressors). But the numerator contains \(\sigma^2\)—the variance of the population error term. This is a population parameter that we cannot observe directly.
So how do we estimate \(\sigma^2\)?
Recall from the homoskedasticity assumption (GM.5) that \(Var(\mu_i | \mathbf{x}_i) = \sigma^2\) for all observations \(i\). Combined with the zero conditional mean assumption (GM.4), which gives us \(E[\mu_i | \mathbf{x}_i] = 0\), we can show that \(\sigma^2 = E[\mu_i^2]\). Let’s work through why.
From Appendix B, the definition of variance is \(Var(X) = E[(X - \mu)^2]\)—the expected squared deviation from the mean. Applying this to \(\mu_i\) and using the fact that \(E[\mu_i] = 0\) from GM.4:
\[Var(\mu_i) = E[(\mu_i - 0)^2] = E[\mu_i^2]\]
And from GM.5, \(Var(\mu_i) = \sigma^2\), giving us:
\[\sigma^2 = E[\mu_i^2]\]
In other words, \(\sigma^2\) is simply the expected value of the squared error terms. If we could observe the true errors \(\mu_i\), we’d just compute their average squared value. But we can’t observe the true errors—they’re the difference between the actual outcome \(y_i\) and the population regression line, which we don’t know.
What we can compute are the residuals:
\[\hat{\mu}_i = y_i - \hat{y}_i = y_i - \hat{\beta}_0 - \hat{\beta}_1 x_{1i} - \dots - \hat{\beta}_k x_{ki}\]
The residuals are the sample analog of the population errors. They measure the difference between the actual outcome and the estimated regression line. Since the residuals approximate the true errors, we can use them to estimate \(\sigma^2\).
It turns out that the average squared residual, adjusted for degrees of freedom, is an unbiased estimator of \(\sigma^2\):
NoteEstimating \(\sigma^2\)
\[\hat{\sigma}^2 = \frac{\sum_{i=1}^{n} \hat{\mu}_i^2}{n - k - 1} = \frac{SSR}{n - k - 1}\]
where \(SSR = \sum_{i=1}^{n}\hat{\mu}_i^2\) is the sum of squared residuals and \(n - k - 1\) is the degrees of freedom (sample size minus the number of estimated parameters).
Why do we divide by \(n - k - 1\) instead of \(n\)? Because we used \(k + 1\) estimated coefficients (\(\hat{\beta}_0, \hat{\beta}_1, \dots, \hat{\beta}_k\)) to compute the residuals. Each estimated coefficient “uses up” one degree of freedom, so we need to correct for this to get an unbiased estimate. This is the same logic behind the degrees-of-freedom correction in the adjusted \(R^2\).
The square root \(\hat{\sigma} = \sqrt{\hat{\sigma}^2}\) is sometimes called the standard error of the regression (SER) or the root mean squared error (RMSE). In R output, this appears as Residual standard error.
5.10.3 From \(\hat{\sigma}^2\) to the Standard Error
Now we can plug our estimate \(\hat{\sigma}^2\) into the variance formula. The standard error of \(\hat{\beta}_j\) is:
\[ se(\hat{\beta}_j) = \frac{\hat{\sigma}}{\sqrt{SST_j(1 - R_j^2)}} \]
The standard error is the estimated standard deviation of the sampling distribution of \(\hat{\beta}_j\). It tells us how much our estimate would typically vary across repeated samples. Every time you see \(se(\hat{\beta}_j)\) in a regression table, a formula, or R output, this is what’s being computed behind the scenes.
TipThe Big Picture
\[Var(\hat{\beta}_j) = \frac{\sigma^2}{SST_j(1-R_j^2)} \xrightarrow{\text{estimate } \sigma^2 \text{ with residuals}} se(\hat{\beta}_j) = \frac{\hat{\sigma}}{\sqrt{SST_j(1-R_j^2)}}\]
We go from a formula involving an unknown population parameter (\(\sigma^2\)) to a fully computable standard error by replacing \(\sigma^2\) with its sample estimate \(\hat{\sigma}^2 = SSR/(n-k-1)\). The standard error is the foundation of statistical inference: t-statistics, p-values, and confidence intervals (covered in the next unit) all depend on it.
5.10.4 Simulation: Does \(\hat{\sigma}^2\) Actually Work?
Let’s verify that \(\hat{\sigma}^2 = SSR/(n-k-1)\) is a good estimator of \(\sigma^2\) with a simulation. We’ll set up a known population where we choose the true \(\sigma^2\), then check whether our estimator recovers it.
Code
set.seed(325)
# --- Population parameters ---
n <- 100 # sample size
true_sigma2 <- 4 # the TRUE error variance (σ² = 4)
n_sims <- 5000 # number of simulations
# --- Run the simulation ---
sigma2_hat <- numeric(n_sims)
for (i in 1:n_sims) {
# Generate data from a known DGP: y = 2 + 3*x1 + 1*x2 + μ
x1 <- rnorm(n)
x2 <- rnorm(n)
mu <- rnorm(n, mean = 0, sd = sqrt(true_sigma2)) # errors with σ² = 4
y <- 2 + 3 * x1 + 1 * x2 + mu
# Estimate the model
reg <- lm(y ~ x1 + x2)
# Compute σ̂² = SSR / (n - k - 1)
residuals_sq <- residuals(reg)^2
sigma2_hat[i] <- sum(residuals_sq) / (n - 2 - 1) # n - k - 1 = 100 - 2 - 1 = 97
}
# --- Visualize the results ---
ggplot(tibble(sigma2_hat), aes(x = sigma2_hat)) +
geom_histogram(fill = "steelblue", color = "white", bins = 50, alpha = 0.8) +
geom_vline(xintercept = true_sigma2, color = "darkred", linewidth = 1.5, linetype = "dashed") +
geom_vline(xintercept = mean(sigma2_hat), color = "darkgreen", linewidth = 1.2) +
annotate("text", x = true_sigma2 + 0.15, y = Inf, vjust = 2,
label = paste0("True σ² = ", true_sigma2),
color = "darkred", size = 4, hjust = 0, fontface = "italic") +
annotate("text", x = mean(sigma2_hat) + 0.15, y = Inf, vjust = 4,
label = paste0("Average σ̂² = ", round(mean(sigma2_hat), 3)),
color = "darkgreen", size = 4, hjust = 0, fontface = "italic") +
labs(x = expression(hat(sigma)^2),
y = "Frequency",
title = expression(paste("Sampling Distribution of ", hat(sigma)^2))) +
theme_minimal(base_size = 14)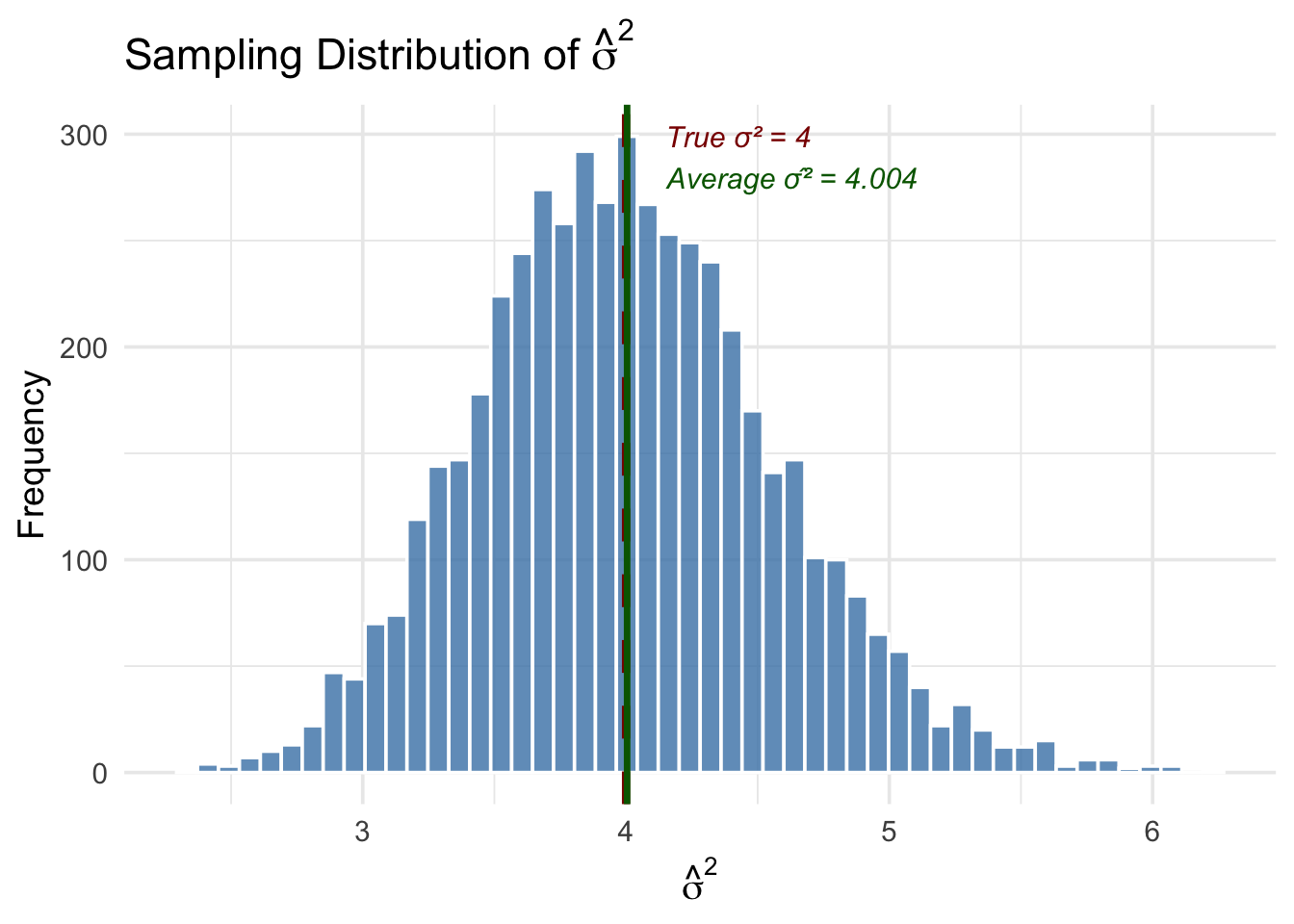
The simulation confirms two important things. First, the average of \(\hat{\sigma}^2\) across all 5,000 samples is very close to the true \(\sigma^2 = 4\)—this is unbiasedness in action. Second, while any single estimate of \(\hat{\sigma}^2\) can be above or below the true value, the distribution is centered in the right place.
What happens if we divide by \(n\) instead of \(n - k - 1\)? Let’s check:
Code
# Compute the naive (biased) estimator that divides by n
sigma2_naive <- sigma2_hat * (n - 2 - 1) / n # convert back: multiply by (n-k-1) then divide by n
bind_rows(
tibble(estimate = sigma2_hat, type = "SSR / (n - k - 1) [unbiased]"),
tibble(estimate = sigma2_naive, type = "SSR / n [biased]")
) |>
ggplot(aes(x = estimate, fill = type)) +
geom_histogram(alpha = 0.6, bins = 50, color = "white", position = "identity") +
geom_vline(xintercept = true_sigma2, color = "darkred", linewidth = 1.5, linetype = "dashed") +
scale_fill_manual(values = c("steelblue", "orange")) +
annotate("text", x = true_sigma2 + 0.1, y = Inf, vjust = 2,
label = paste0("True σ² = ", true_sigma2),
color = "darkred", size = 4, hjust = 0, fontface = "italic") +
labs(x = expression(hat(sigma)^2),
y = "Frequency",
fill = "Estimator",
title = "Why the Degrees-of-Freedom Correction Matters") +
theme_minimal(base_size = 14) +
theme(legend.position = "bottom")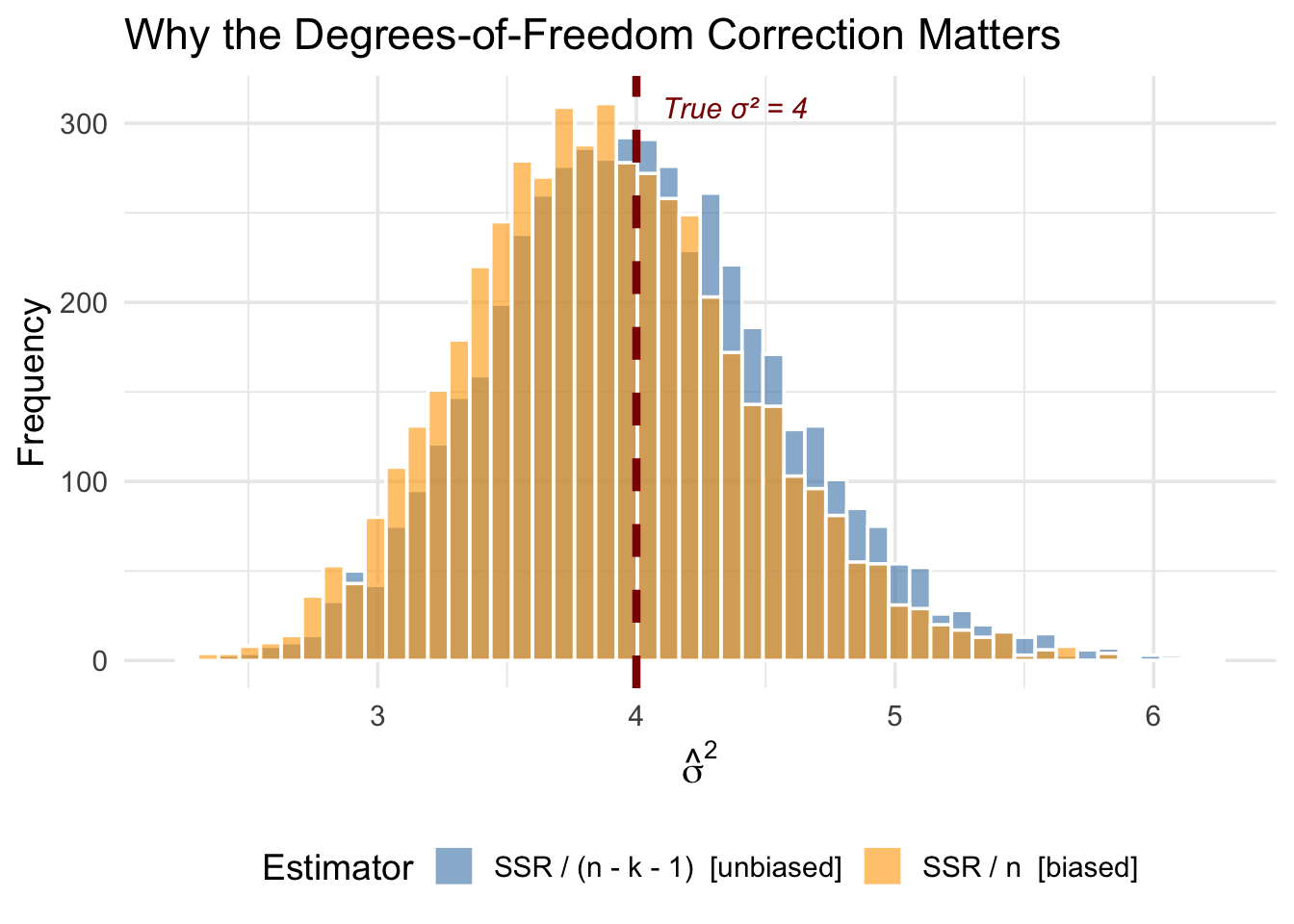
The orange distribution (dividing by \(n\)) is shifted to the left—it systematically underestimates \(\sigma^2\). The degrees-of-freedom correction fixes this bias. The intuition is that the residuals are computed from the estimated regression line, which is already chosen to fit the data as closely as possible. This makes the residuals systematically smaller than the true errors, and dividing by \(n - k - 1\) instead of \(n\) corrects for this.
5.11 The Bias-Variance Tradeoff
Should you include a variable in your regression? The answer depends on a tradeoff.
5.11.1 The Costs of Omitting a Relevant Variable
If a variable truly belongs in the model (\(\beta_2 \neq 0\)) and is correlated with \(x_1\), omitting it causes bias. Your estimate systematically misses the true value.
5.11.2 The Costs of Including an Irrelevant Variable
What if you include a variable that doesn’t belong (\(\beta_2 = 0\))?
From the OVB formula: \[E[\hat{\beta}_1] = \beta_1 + (0) \cdot \tilde{\delta}_1 = \beta_1\]
No bias! Including an irrelevant variable doesn’t bias your estimate.
But look at the variance formula. Including an extra variable increases \(R_1^2\) (the correlation between \(x_1\) and other variables), which increases the variance of \(\hat{\beta}_1\).
Including irrelevant variables inflates variance without reducing bias.
5.11.3 The Tradeoff
| Action | Bias | Variance |
|---|---|---|
| Omit relevant variable | Increases | Decreases |
| Include irrelevant variable | No change | Increases |
This is the bias-variance tradeoff:
- If you’re too conservative (omit too many variables), you risk bias
- If you’re too liberal (include everything), you inflate variance
5.11.4 Practical Guidance
There’s no perfect solution, but some principles help:
Include variables you have strong theoretical reasons to believe are confounders. Use economic theory and prior research to guide variable selection.
Be cautious about highly correlated controls. If two controls are very highly correlated with each other, including both can dramatically inflate variance.
Larger samples help. As \(n\) increases, variance decreases, making the “include it just in case” strategy less costly.
Check how estimates change. If adding a control substantially changes your coefficient of interest, that control is probably important.
5.12 Simulation: Bias vs. Variance
Let’s see the bias-variance tradeoff in action with a simulation. We generate two populations—one where \(x_2\) is irrelevant (\(\beta_2 = 0\)) and one where \(x_2\) is relevant (\(\beta_2 \neq 0\))—then repeatedly estimate \(\hat{\beta}_1\) using either the short model (omit \(x_2\)) or the long model (include \(x_2\)).
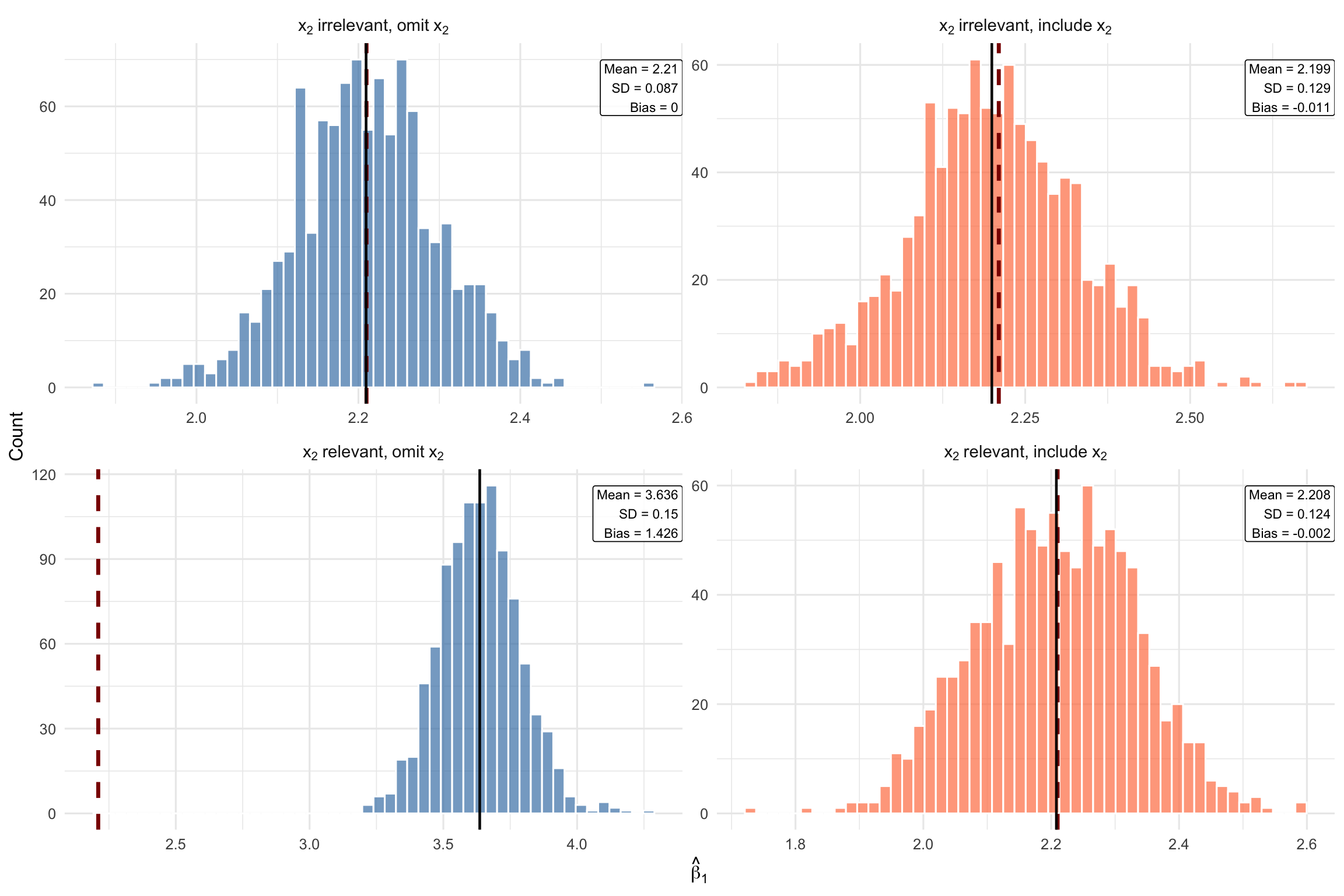
Each panel shows one of the four possible scenarios:
Case 1 (top-left): \(x_2\) is irrelevant and we omit it. Both bias and variance are small. This is the best case—we correctly leave out a variable that doesn’t belong.
Case 2 (top-right): \(x_2\) is irrelevant but we include it anyway. The estimates are still centered on the true value (no bias), but the distribution is wider (higher variance). Including an irrelevant variable costs us precision for no benefit.
Case 3 (bottom-left): \(x_2\) is relevant but we omit it. The distribution shifts away from the true \(\beta_1\)—this is omitted variable bias. Even though the variance is low, the estimates are systematically wrong.
Case 4 (bottom-right): \(x_2\) is relevant and we include it. The distribution is centered on the true value (no bias), though variance is slightly higher than Case 1. This is the correct specification—the variance cost is worth paying to eliminate bias.
5.13 Summary
This chapter extended OLS to the multivariate case, allowing us to control for confounding variables.
5.13.1 Key Takeaways
Multivariate OLS includes multiple independent variables: \[y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_k x_k + \mu\]
Coefficients have ceteris paribus interpretations: \(\beta_j\) is the effect of \(x_j\) holding all other variables constant
The zero conditional mean assumption now requires \(E[\mu | x_1, \ldots, x_k] = 0\)—more plausible with good controls
Multivariate OLS is like matching: It compares observations within groups defined by control variables
The OVB formula tells us the direction of bias from omitting a variable: \[\text{Bias} = \beta_2 \cdot \tilde{\delta}_1\]
There’s a bias-variance tradeoff: Omitting relevant variables causes bias; including irrelevant variables inflates variance
Perfect multicollinearity occurs when one variable is an exact linear function of others; it must be avoided
5.14 Check Your Understanding
OVB Direction Practice: For each scenario, determine the likely direction of bias.
Practice: Interpreting Multivariate Regression Output
Regression 1: A researcher estimates the determinants of house prices:
Dependent variable: price (house price in $1000s)
Estimate Std. Error
(Intercept) 50.23 12.45
sqft 0.15 0.02
bedrooms -8.72 3.21
bathrooms 24.56 4.89
n = 546, Adjusted R-squared = 0.68
Regression 2: An economist studies student test performance:
Dependent variable: test_score (standardized, mean=0, sd=1)
Estimate Std. Error
(Intercept) -0.892 0.156
hours_studied 0.045 0.008
parent_college 0.312 0.067
free_lunch -0.287 0.071
n = 1,200, Adjusted R-squared = 0.23
Note: parent_college = 1 if at least one parent has college degree; free_lunch = 1 if eligible for free lunch program (proxy for low income)
TipShow Explanation
In multivariate regression, \(\beta_1\) is the partial effect of \(x_1\) on \(y\), holding \(x_2\) (and all other included variables) constant. This is the ceteris paribus interpretation.
The multivariate zero conditional mean assumption requires that the error term have mean zero for all combinations of the independent variables, not just unconditionally.
Perfect multicollinearity means one variable is a perfect linear combination of others (like including income in dollars and income in thousands, or including all categories of a dummy variable plus an intercept). Simple correlation between variables is not perfect multicollinearity.
The adjusted R-squared penalizes for adding more variables, preventing the mechanical increase that happens with regular R-squared when you add irrelevant variables.
From the OVB formula: \(\text{Bias} = \beta_2 \cdot \tilde{\delta}_1\). Bias equals zero if either \(\beta_2 = 0\) (the omitted variable doesn’t affect \(y\)) or \(\tilde{\delta}_1 = 0\) (the omitted variable is uncorrelated with \(x_1\)).
Including an irrelevant variable doesn’t cause bias (since \(\beta_2 = 0\) in the OVB formula), but it does increase variance through the \((1 - R_j^2)\) term in the variance formula.
Income is positively correlated with both exercise and health. $ = (+)(+) = $ Positive. We overestimate the effect of exercise because part of what we’re measuring is actually the effect of income.
More funding means smaller classes (negative correlation: \(\tilde{\delta}_1 < 0\)) and higher scores (\(\beta_2 > 0\)). $ = (+)(-) = $ Negative. The estimate of class size’s effect is too negative—we attribute to large classes what is actually due to low funding.
When adding a control causes the coefficient of interest to change substantially, it suggests the original estimate was confounded. Here, part of what looked like a “return to education” was actually capturing the fact that higher-ability people get more education and earn more.
Regression Interpretation Questions:
- The coefficient on sqft is 0.15, meaning each additional square foot is associated with $150 more (since price is in $1000s). For 100 square feet: \(100 \times 0.15 = 15\), which is $15,000.
The coefficient on bedrooms has a ceteris paribus interpretation: holding square footage and bathrooms constant, an additional bedroom is associated with $8,720 lower price. This doesn’t mean bedrooms reduce prices overall—it’s the partial effect.
The key is “holding square footage constant.” If total space is fixed, adding a bedroom means dividing that space into more (smaller) rooms. Buyers may prefer fewer, larger rooms to more cramped ones. This illustrates why we must interpret multivariate coefficients carefully—they hold other variables constant.
The coefficient on hours_studied is 0.045, so 10 additional hours predicts: \(10 \times 0.045 = 0.45\) standard deviations higher. Since the outcome is standardized, we interpret in standard deviation units.
The coefficient on parent_college (0.312) is the difference in predicted test scores between students with and without college-educated parents, holding study hours and free lunch status constant. Since test scores are standardized, this is 0.312 standard deviations.
The naive coefficient (0.062) is larger than the controlled coefficient (0.045) because of omitted variable bias. Students from advantaged backgrounds (college-educated parents, higher income) likely study more AND have other advantages (better schools, tutoring, resources) that boost scores. The naive estimate conflates the effect of studying with these background advantages.